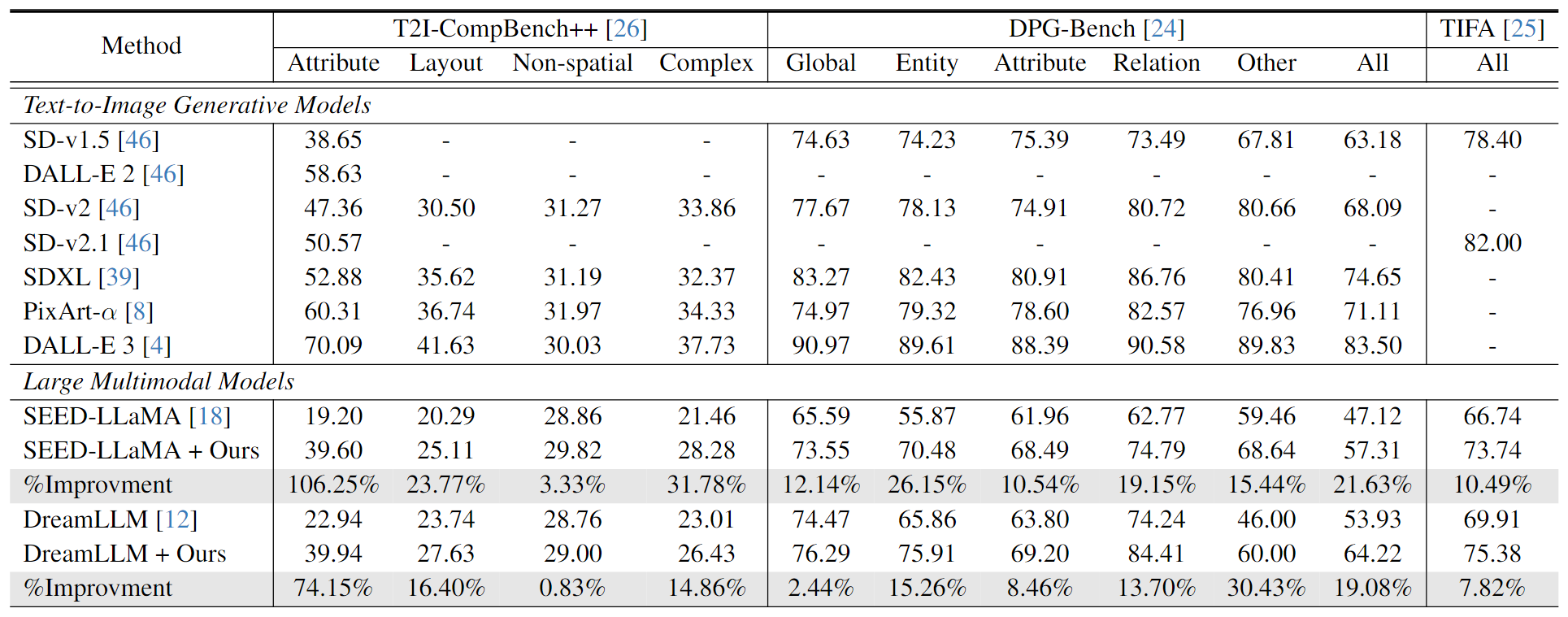
Large Multimodal Models (LMMs) have demonstrated impressive capabilities in multimodal understanding and generation, pushing forward advancements in text-to-image generation. However, achieving accurate text-image alignment for LMMs, particularly in compositional scenarios, remains challenging. Existing approaches, such as layout planning for multi-step generation and learning from human feedback or AI feedback, depend heavily on prompt engineering, costly human annotations, and continual upgrading, limiting flexibility and scalability. In this work, we introduce a model-agnostic iterative self-improvement framework (SILMM) that can enable LMMs to provide helpful and scalable self-feedback and optimize text-image alignment via Direct Preference Optimization (DPO). DPO can readily applied to LMMs that use discrete visual tokens as intermediate image representations; while it is less suitable for LMMs with continuous visual features, as obtaining generation probabilities is challenging. To adapt SILMM to LMMs with continuous features, we propose a diversity mechanism to obtain diverse representations and a kernel-based continuous DPO for alignment. Extensive experiments on three compositional text-to-image generation benchmarks validate the effectiveness and superiority of SILMM, showing improvements exceeding 30% on T2I-CompBench++ and around 20% on DPG-Bench.